논문 리뷰: The Mythos of Model Interpretability
본 글은 Lipton의 “The Mythos of Model Interpretability”을 기반으로 쓰여졌습니다.
0. Abstract
-
지금 시대에 많은 머신러닝 모델은 뛰어난 예측 성능을 보여주고 있다. 하지만 우리가 실제로 그런 모델을 믿을수 있을까? 그게 실제 세계에 대해서 정말로 말하고자 하는게 무엇이라 생각하는가?
-
우리들은 모델이 단순히 예측력이 뛰어날 뿐아니라 이제 해석가능해서 우리가 실제로 이해할수 있기를 원한다.
-
하지만 많은 경우 해석가능성(interpretability)에 대해서 정확하게 정의내리지 못한다.
-
이 포스팅에서는 해석가능성에 대한 다양한 동기와, 해석 가능한 모델의 성질들에 대해서 다룰것이다.
-
또한 흔히 하는 선형모델이 복잡한 딥러닝모델보다 더 해석가능하단 생각에 의문을 제기할 것이다.
1. Introduction
-
해석 가능성은 단일화된 하나의 개념이 아니라, 몇개의 서로다른 아이디어들을 반영한다.
-
이 논문은 주로 지도학습(supervised learning)의 경우에 초점을 맞춰서 설명한다. (연구자들의 주된 관심이 abstract의 마지막 부분에 있던 선형모델과 딥러닝 모델의 해석 가능성측면에서의 비교여서 그런것 같음.)
-
머신러닝 문제 상황과 실제 현실의 문제는 완변하게 매칭이 되지 않을수 있다. 이는 머신러닝의 간단한 최적화 과정이 우리의 복잡한 실제상황을 반영하지 못하기 때문에 발생하는 문제이다.
간단한 예시로 의학연구 분야에서 담배와 암의 인과관계를 알아보고싶은데 이 경우 머신러닝 최적화는 주로 에러를 최소화 하는 방향으로 작동하기 때문에 상관계수 측면에서만 작동할수 있다. (상관관계와 인과관계의 차이점을 구분해야함.)
-
사람들은 자신의 행동의 이유를 다른 사람에게 설명할 수 있어서 사람의 의사 결정은 해석가능하다 한다. 그러나 사람들이 자신의 뇌의 작동 방식이나 구성같은걸 명백하게 설명할수 있는 사람은 없을것이다. 그래도 위와 같은 설명은 유용할 수 있다. 이런 측면에서 해석가능성이란, 어떤 종류의 유용한 정보들은 전달해 주는것을 말한다.
-
많은 다른 논문에서 해석가능성과 understandability을 동일시 한다. 때때로 understandability한 모델은 투명한 모델(transparent model), understandability하지 못한 모델은 블랙박스 모델(black box model)이라 불린다. 이때 실제로 투명한 모델만이 해석 가능할까??
-
Post-hoc interpretation은 모델의 작동방식에 상관없이 모델을 해석하려는 시도이다. 여기서 아주 쉽게 예시를 들면 인간들은 뇌가 어떻게 작동하는지 모름에도 자신의 행동 원리를 설명하는데, 보통의 관념과 모순되게 블랙 박스 모델도 해석 가능하다 볼 수 있을 것이다.
2. Desiderata of Interpretability Research
아직도 해석가능성의 형식적의 정의는 명확하지가 않다. 이 논문의 목적중 하나는 이것의 보다 명확한 정의를 내리는 것이다.
그러기 위해서 해석가능한 연구의 요구사항을 먼저 살펴 볼 것이다.
생각을 해보면 연구를 진행할때 모델을 만들기 위해서 사용한 loss나 평가하기 위해 사용한 evaluation metric과 실제로 우리에게 필요한 수치가 다를 수 있는데 이럴때 해석가능성이 요구될 수 있다.
해석가능한 연구들이 요구하는 사항들은 다음과 같다.
또한 해당 페이퍼는 이 부분을 이런식으로 설명했으나, 조금 더 쉽게 설명하면 model interpretability가 필요한 이유 혹은 동기로 생각 하면 될것 같다.
2.1. Trust
신뢰성(Trust)란 무엇일까? 어떤 모델이 잘 작동한다는 믿음을 주면 그게 모델을 신뢰할수 있는 지표가 되는것일까? 그렇다면 그냥 퍼포먼스가 좋은 모델이 신뢰성이 높은것이니 해석가능성이 크게 의미가 없을 것이다.
신뢰성은 크게 두가지 측면에서 생각해 볼 수 있다.
-
훈련상황과 실제 상황이 괴리가 있더라도 모델이 실제 상황에 잘 작동할 거란 믿음. 주어진 데이터를 기반으로 모델이 훈련하는것과 실생활에 적용되는 상황은 차이가 있을 수 있는데 그럴때에도 모델이 잘 작동할 거라 생각하는걸 모델을 신뢰한다 생각할 수 있을 것이다.
-
우리가 모델을 컨트롤하는걸 포기해도 된다는 생각. 예컨데 우리가 고양이 사진을 고양이라고 맞출 때 모델이 개라고 한다면 우리는 그 모델을 신뢰할 수 없고, 그에 따라 모델을 계속 컨트롤하는걸 포기한다면 그만큼의 비용이 들것이다. 반면 A, B, C가 적힌 사진에서 우리가 분류한것과 모델이 분류한것이 일치한다면 우리는 모델을 신뢰할 수 있고 모델을 컨트롤 하는걸 포기해도 모델이 알아서 잘 하니까 그만큼의 비용이 들지 않을 것이라 볼 수 있다.
이 두 상황에서 모델을 trust할만 하다고 생각할 수 있다.
2.2. Causality
지도학습 알고리즘으로 얻어지는 관계는 인과관계를 보장하지는 못한다. 우리가 A와 B의 상관관계를 볼때 그것에 영향을 미치는 다른 요인인 C (Confounder)는 언제든지 존재할 수 있다.
그러나, 우리는 지도학습을 해석함으로 써 두 변수사이의 관계에 대한 가설을 이끌어내서 그것에 대한 가설 검정을 진행 할 수 있기를 희망한다. 그래서 몇 몇 학자들이 regression tree나 Bayesian neural network의 사용을 강조하는 이유이다.
하지만 아직도 이러한 방법들은 해당 도메인의 사전지식에 많이 의존하는 한계가 있다.
2.3. Transferability
우리가 보통 모델의 일반화 능력을 평가할때는 주어진 데이터 셋을 랜덤하게 training set과 test set으로 나눈 다음, training set을 통해 모델을 훈련한 뒤에 test set을 사용해서 모델의 일반화 능력을 평가한다. 그러나 인간을 기준으로 생각했을때, 사람은 아에 다른 상황에서 배운것을 익숙하지 않은 상황에 사용하는데 있어서 더 높은 일반화 능력을 가지고 있다.
심지어 아주 해석력이 높다고 알려진 모델 또한 이런 측면에서는 부족한 경우가 있다. 예를 들어 신용평가 점수를 예측 할 때 해석의 용이성을 위해서 로지스틱선형회귀(logistic linear regression)을 사용하는 경우가 많은데, 이 때 악의를 가진 사람이 특정 변수를 조작하면 쉽게 신용점수를 높일 수 있단것이 알려져 있다. 이런식으로 적극적으로 모델에 개입하고 훈련상황과 다른 상황을 만들 때 모델의 예측력은 떨어질 수 있다.
이런상황을 방지하기 위해 해석가능한 연구는 전이가능성(Transferability)를 요구한다.
2.4. Informativeness
우리는 모델의 outputs에 기반해서 결정을 내릴 때도 있지만, 그렇지 않고 모델이 주는 그 외 다른 정보를 사용해서 결정을 내릴 수도 있다. 머신러닝 모델의 목적은 오차를 줄이는 것이지만, 실제 그 역할은 실생활에 유용한 정보를 주는것임을 명심해야 한다. 답만으로는 아무런 역할을 하지 못할 수 있다. 극단적인 예시로 학생이 교수에게 뭔가를 물어봤을때 교수가 답만을 준다면 그건 그 학생에게 큰 의미가 없을 수 있다. 교수가 아무리 똑똑하더라도, 교수의 답을 학생이 이해할 수 없다면 의미가 없을 것이다.
여기서 모델을 해석함으로써 모델의 결과값뿐만아리날 추가적인 정보를 얻어 그것을 사용하는게 매우 중요한다.
2.5. Fair and Ethical Decision-Making
자동화된 알고리즘이 결정을 만듦에 따라 정치인, 언론, 연구자들이 모델의 해석가능성에 많은 관심을 기울이기 시작했다.
유튜브의 추천 알고리즘, 뉴스 알고리즘 등 우리는 많은 알고리즘에 둘러쌓여 있어 이는 시기적절한 논의로 보인다.
하나의 예시로 법원에서 재범률을 예측하는 모델을 사용해 예측된 재범률이 높은 사람은 계속 수감하고 그렇지 않고 낮은 사람은 풀어준다고 하자. 이 때, 재범률을 예측하는 모델 알고리즘이 특정 인종에 따라 재범률 예측에 차별을 하지 않는지 어떻게 알 수 있을까? 이런 공평함과 윤리성 측면에서 모델 해석이 강조되고 있다.
3. Properties of Interpretable Models
- Transparency
모델이 돌아가는 방식
- Post-hoc
모델이 우리에게 무엇을 말해주는가?
3.1. Transparency
투명성(Transpaency)는 소위 블랙 박스(Black-Box)의 반대 개념이다. 모델이 어떻게 작동하는지 그 원리에 대해서 잘 이해하고 있는지에 대한 문제로 받아들일 수 있다.
3.1.1. Simulatability(재현가능성)
재현가능성(simulatability)의 엄밀한 정의는 사람이 한번에 전체 모델을 확인할 수 있는지 여부이다. 이 정의는 모델이 얼마나 간단한지에 대한 내용으로 이해될 수 있다. 변수와 입력값이 다 주어졌을 때 사람이 직접 출력값을 적절한 시간내에 계산할 수 있는지의 여부로도 생각할 수 있다. 이는 sparse model인 lasso regression이 일반적인 선형회귀 모형보다 더 해석가능하다는 의견과도 맥락을 같이한다. 다만 이런 측면에서 “적절한 시간” 이건 상당히 주관적일 수도 있고, 선형 모델, 트리모델 등도 모델이 커지면 사람이 계산하기 어려워지므로 본질적으로는 해석가능하다 말할수 없다.
3.1.2. Decomposability
재현가능성(simulatability)이 전체 모델에 관한 내용이라면, Decomposability은 각각의 개별 모수에 관한 내용이다. 우리가 트리 모델을 볼때 각 노드를 통해서 결정을 내리거나 혹은 선형 회귀 모형에서 각 계수가 어떻게 입력과 출력의 관계를 설명하는지를 확인할 수 있는걸로 보면 된다.
이러한 설명방법은 널리 알려져 있고 유용할 수 있지만, 주의해야 할 점이 있다. 변수 선택이 어떻게 되냐, 그리고 각 특성들 사이의 상관관계에 따라 계수값이 달라지고 그에 따라 각 계수의 부호까지 바뀌어 해석 자체가 달라질 수 있음을 유의 해야한다. (Multicollinearity problem).
3.1.3. Algrorithmic transparency
학습 알고리즘 그 자체에 대한 문제이다. 모델 알고리즘의 유일성(uniqueness),비편향성(unbiasedness), 일치성(consistency)등을 이론적으로 확인할 수 있는지에 대한 내용이다. 예를들어 선형회귀 모형의 경우 우리는 근이 유일하고 그게 일치성을 가짐을 보일 수 있지만, 복잡한 신경망 모델의 경우 이러한 내용을 확인하기 어려운 문제가 있다.
3.2. Post-hoc Interpretability
Post-hoc interpretability는 이미 학습된 모델에서 유용한 정보를 추출해 내는 방법이다. 이 방법은 모델이 정확하게 어떻게 돌아가는지, 즉 알고리즘적인 설명은 하지 않으나 그럼에도 불구하고 여러 유용한 정보들을 알려줄 수 있다.
또한 이 방법의 이점은 이건 모델의 예측력을 저하시키지 않으면서 행해지는 방법이므로 모델 퍼포먼스를 손상시키지 않는다.
Post-hoc interpretability는 여러가지 방법이 있으며 이는 다음과 같다. 또한 해당 논문에서는 여러 논문을 참고해 해당 방법을 간단하게 소개하는 정도로 했으므로 이 포스팅 역시 너무 자세하게 설명하지 않도록 하겠다.
3.2.1. Text explanations
model A가 있다면 그 모델을 설명하는 또 다른 자연어 처리 모델 model B를 model A의 가능도가 최대가 되는 방식으로 만들어 model A를 설명하고자 하는 방법이다.
이 방법을 소개한 논문은 다음과 같다.
- Krening(2016)
- McAuley & Leskovec(2013)
3.2.2. Visualization
모델이 학습한 내용을 시각화 하는 방법이다.
-
t-SNE는 고차원 분포를 시각화하는 방법인데, 가까운 데이터 포인트들을 위주로 2차원으로 축소시켜 시각화해 보여준다. 이는 다음에 기회가 있다면 해당 내용만 따로 해서 포스팅할 것이다.
-
또는 다른 방법은 각 hidden layer를 학습시키는데 있어서 경사하강법을 할 때 사용되는 input value를 다른 값으로 바꿔 해당 결과들의 차이를 보여주는 방법이 있다. 이는 Mordvintsev(2015)가 제안한 방법이다.
3.2.3. Local explantions
학습된 모델 전체를 보는게 아닌 특정한 점 한개를 중심으로 모델을 해석하고자 하는 방법이다.
- Saliency map(Wang, 2015): Input vector가 주어졌다면 옳게 분류된것에 해당되는 벡터의 gradient를 계산해 나타내는 방법이다. 이 때 이 gradient가 큰 부분이 변화하면 결과값에 큰 영향을 줄거라 해석할 수 있다.
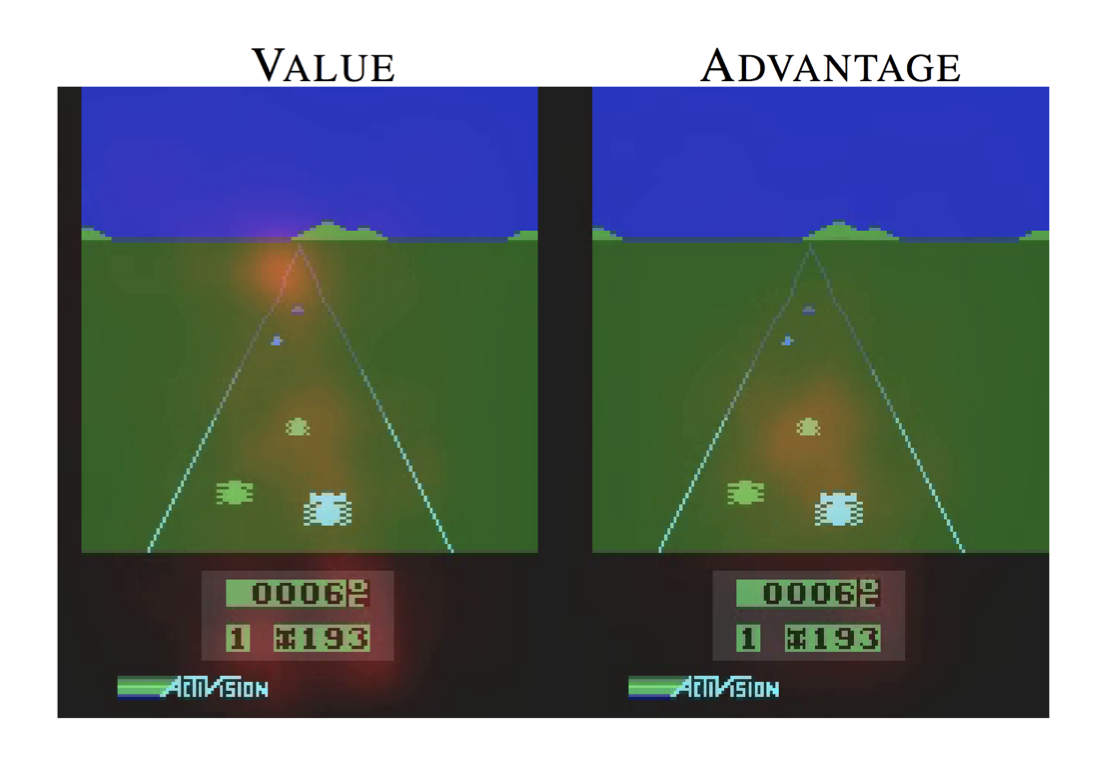
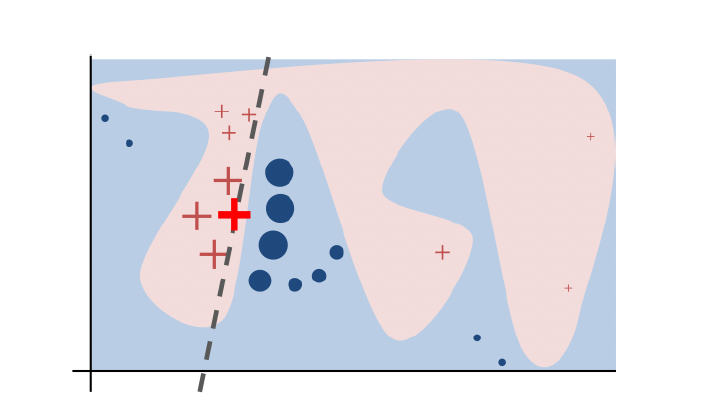
- Lime(Local interpretable Model-Agnostic Explanations, Ribeiro,2016)
특정한 모델에 상관없이 적용되는 방법으로, 어떤 점을 중심으로 그 점 주위의 몇개의 점을 가지고 선형 모델을 적용시켜 주어진 모델을 해석하고자 하는 방법이다.
이 역시 t-sne와 마찬가지로 별도의 포스팅에서 다루도록 하겠다.
3.2.4. Explaination by example
학습된 모델에 의해서 우리가 설명하고자 하는 data point와 근접한 다른 data points들을 살펴보는 방법이다. 비유를 들면 특정 종양이 악성 종양과 비슷하게 생겼다면 그 종양을 악성으로 분류하는데 보다 설명력이 있을것이다.
Caruana의 1999년 논문에 의하면, 심층 신경망을 구현하면 특정 data point에 대한 결과값을 얻을수 있을 뿐아니라, 각 hidden layer가 활성화 되는 정도를 통해 그 data point와 근접하다 생각되는 다른 data points들을 얻을 수 있는데 이것을 통해 처음 주어진 data point를 설명하려는 시도로 생각할 수 있다.
4. Discussion
지금까지 모델의 해석가능성이 필요한 동기와 그것을 얻기 위한 방법들에 대해서 살펴보았다. 이 장에서는 이와 관련된 몇가지 논의 사항을 제안한다.
4.1. Linear models are not strictly moore interpretable than deep neural networks
선형모형이 다층신경망 모형보다 더 해석가능하단건 널리 알려진 사실이다. 그러나 이 논문의 저자들은 이에 대해 의문을 제기한다. 만약 변수의 개수가 많아진다면 transparency측면에서 선형모형 역시 simulatability와 decomposability를 잃을 수 있다고 말한다.
또한 다층 신경망의 경우 input들의 특성을 그대로 사용해 모델을 적합시켜 보다 더 직관적으로 해석가능할 여지가 있지만, 선형모델의 경우는 그런 특성들을 다 전처리해서 모델에 넣을수 있는 형태로 바꿔야 되기때문에 오히려 해석가능한 측면에서 더 비효율적이란 의견이다. 그래서 선형모델을 사용해 해석하는것 보단 다층 신경망을 적합하고 앞에서 배운 여러가지 post-hoc기법들을 사용하는게 더 나을수도 있다 주장한다.
또한 실생활의 여러가지 문제에 대해 선형모델을 사용해 해석하는게 지금까지 많은 도움이 되어왔지만, 그게 다층 신경망 보다 더 좋다는 이론적 배경은 없다 주장한다.
4.2. 그 외
-
Interpretability란 용어를 사용할 때는 이 용어가 어떤 의미에서 사용된건지 명확히 해야한다. 특히 그것이 transparency를 의미하는것인지 혹은 다른 post-hoc 방법을 사용했으면 그 목적을 밝혀야한다.
-
Interpretability를 올리려는 시도가 다른 이해관계와 충돌될 수 있다. 에컨데 의학분야에서 신뢰성을 주기 위해 model interpretability를 개선하려는 시도가 모델의 power를 약화시켜 장기적인 health care를 향상시키는데 악영향을 줄 수 있다.
5. Conclusion
이 논문은 많이 사용되고 중요하지만 그 의미가 분명하지 않은 모델의 해석가능성(interpretability)에 대해 그 의미를 명확히 하고, 해석가능성이 필요한 이유에 대해서 설명한다.
해석가능성이 필요한 이유는 5가지 이유(:Trust, Causality, Transferability, Informativeness, Fair and Ethical Decision-Making)이 있었다. 또한 해석가능성을 보여주기 위한 2가지 성질은 Transperency와 Post-hoc 방법들이 있었다.
또한 저자들은 많은 머신러닝 학회에서 해석가능성을 이러한 고려없이 사용하는것에 대해서 염려하고 있으며, 독자들에게 해석 가능성과 관련된 논문을 쓸 때에는 위와 같은 방법으로 해석가능성을 분명히 해야한다 강조하며 글을 마무리한다.
6. 참고문헌
-
Lipton, Zachary C. “The Mythos of Model Interpretability.” (2016).
-
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. ““Why Should I Trust You?”.” KDD’16: PROCEEDINGS OF THE 22ND ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING 13-17 (2016): 1135-144.
댓글남기기